Agentgateway v1.3.0: LLM Consumption, Reimagined
agentgateway v1.3.0 ships a purpose-built LLM UI, first-class cost tracking, virtual models with weighted/conditional/failover routing, reusable providers & guardrails, and 13 new LLM providers.
Agentgateway v1.3.0 is here — and it’s the biggest leap yet in how you consume LLMs. We rebuilt the experience around the way developers actually work: one endpoint, the model in the request body, and every concern that used to demand a separate tool — cost, security, guardrails, observability — now handled right at the gateway. No custom proxies, no SDK sprawl, no waiting on the next provider release to catch up.
Here’s what landed:
- A brand-new, purpose-built UI — native LLM, MCP, and Traffic views
- AI Cost & Analysis — token and dollar cost, fully attributed, in logs, traces, metrics, and the UI
- Virtual models — weighted, conditional, and failover routing
- Reusable providers & guardrails — define once, reference everywhere
- 13 new LLM providers — Mistral, Hugging Face, Cohere, and ten more
All of it aligned with the model-based routing pattern every developer already expects. This is what a true AI-native gateway feels like.
The new UI — built for the LLM-first world
We didn’t just refresh the UI. We rebuilt the mental model around how you actually consume LLMs and MCP services. Pick the capabilities you need on first launch and you’re off:
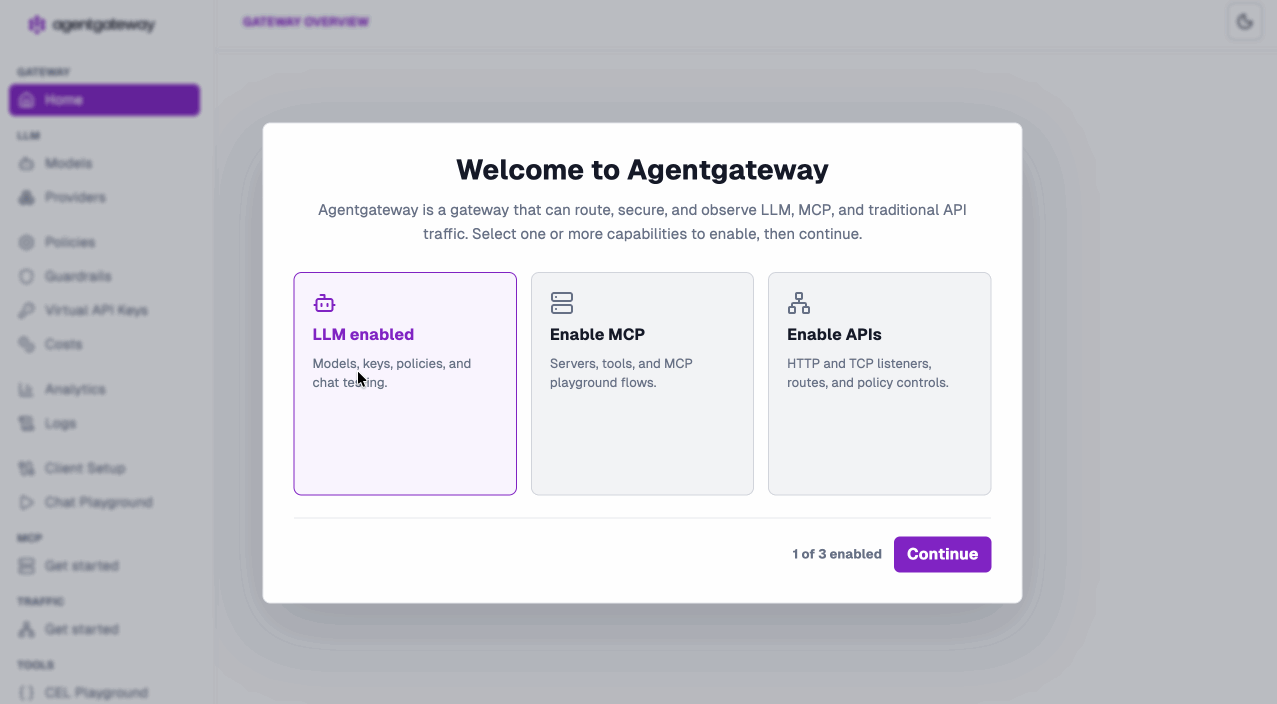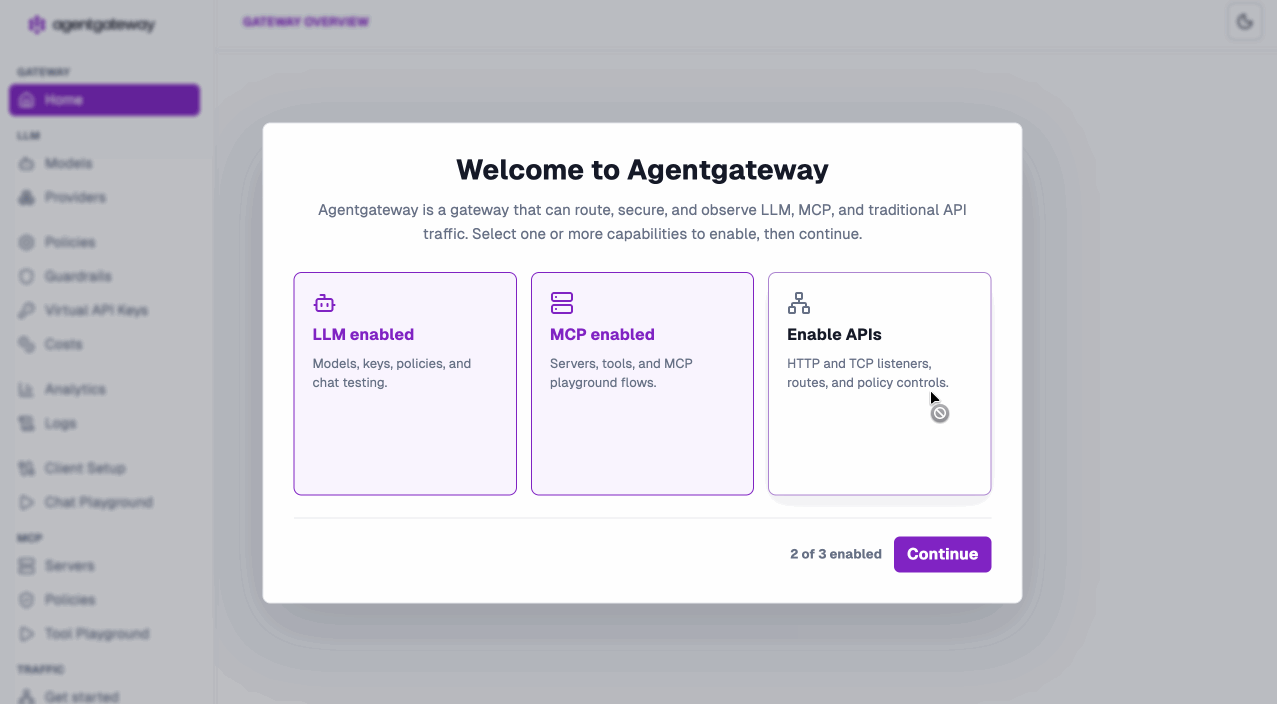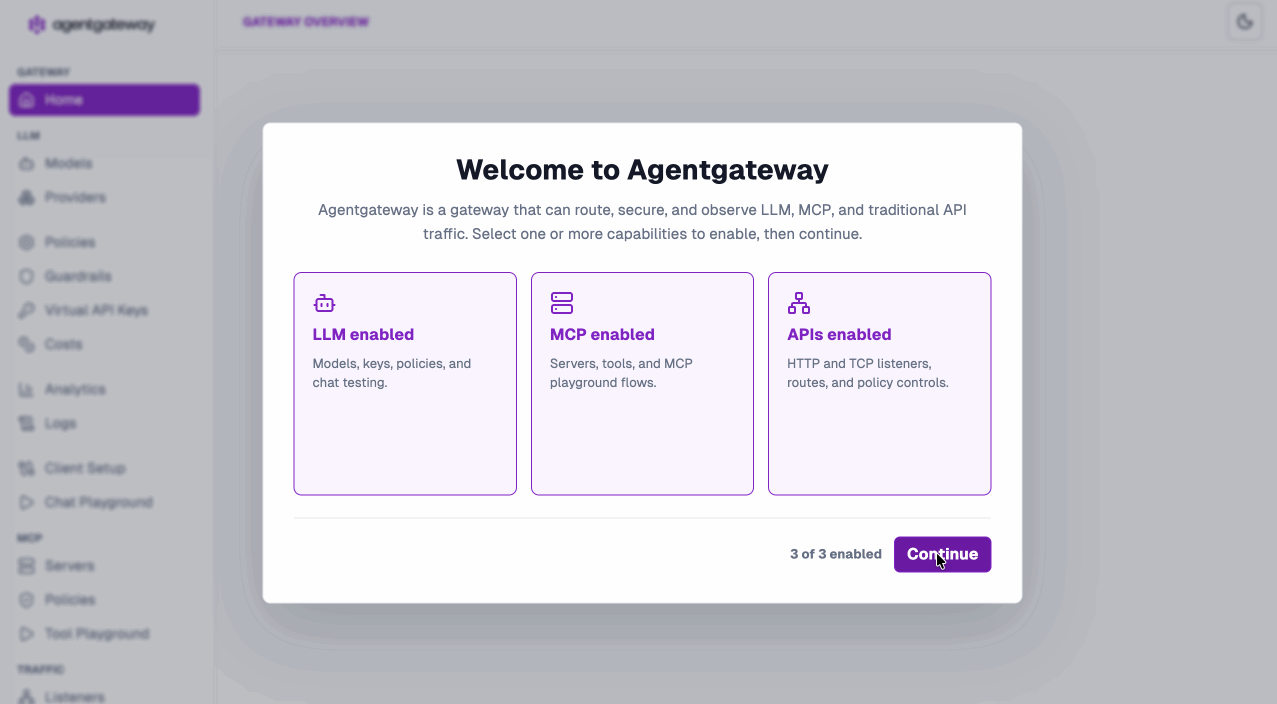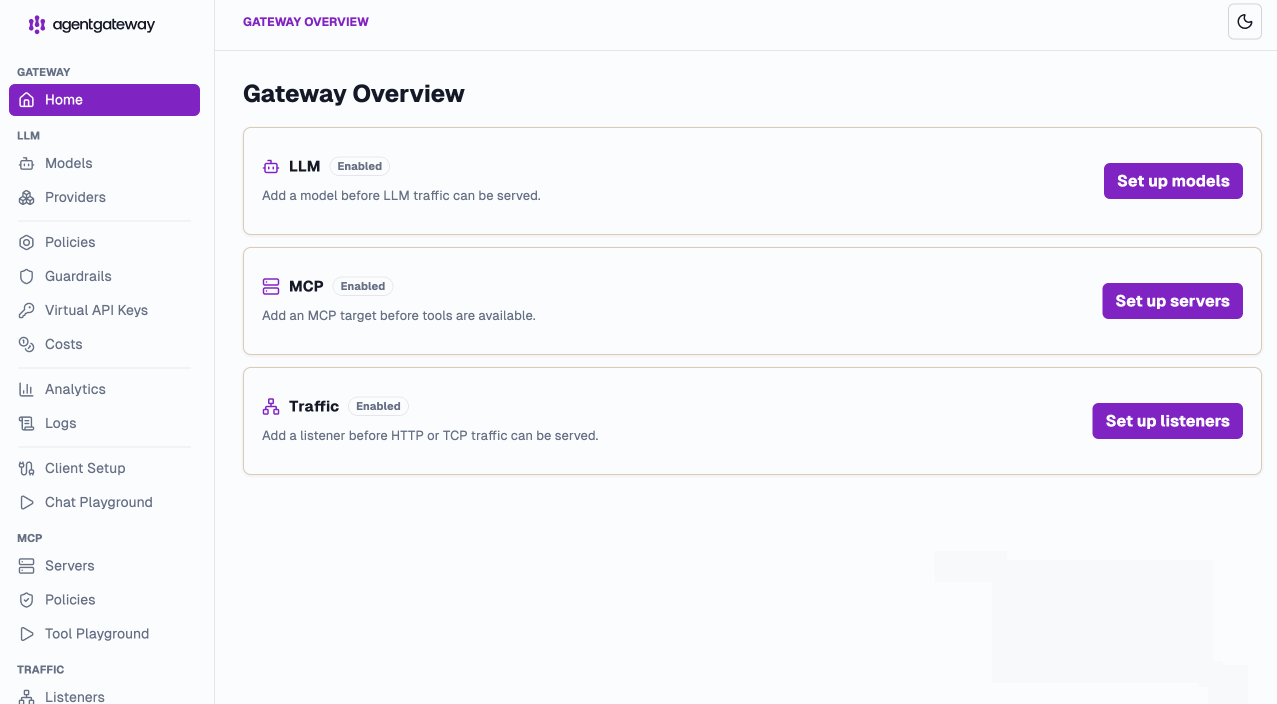
Everything is now organized into three clean, native views:
- LLM — models, providers, policies, guardrails, costs, virtual API keys
- MCP — servers, tools, resources, auth
- Traffic — the classic Gateway API experience you already know
Onboard providers and models in seconds. Point an incoming model match at a provider and you’re routing — add provider-backed models or virtual models from the same screen.
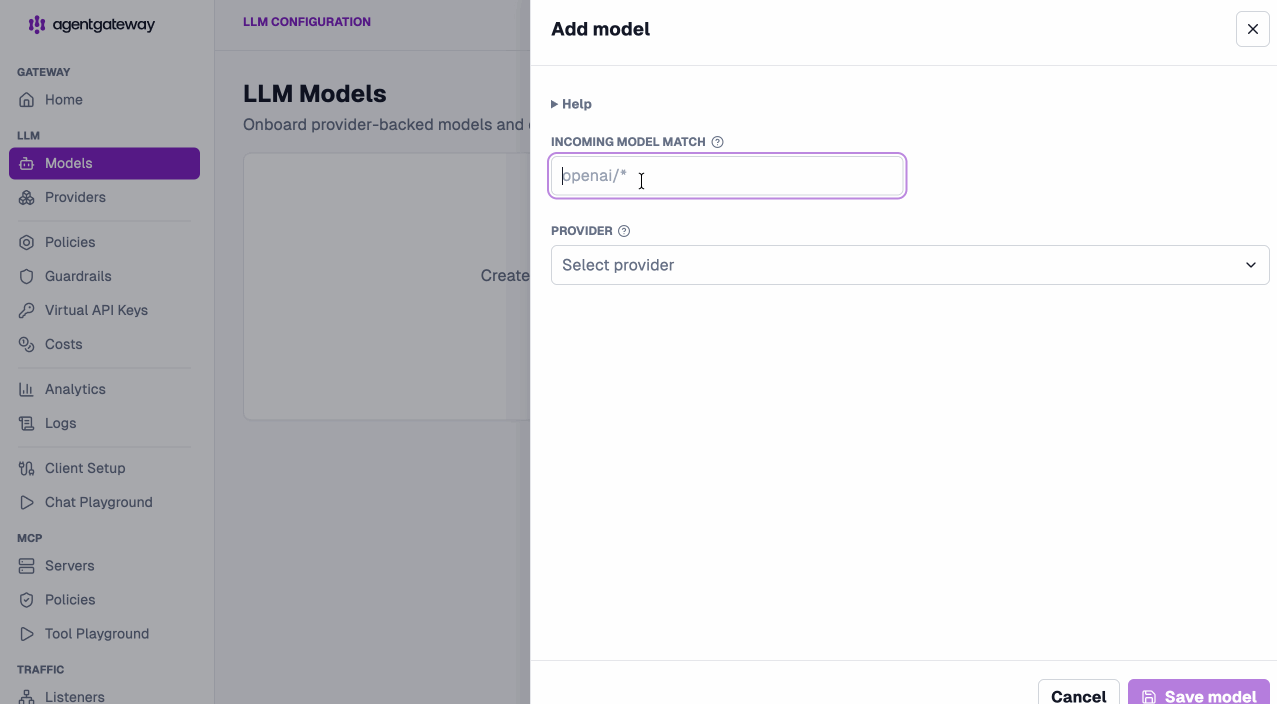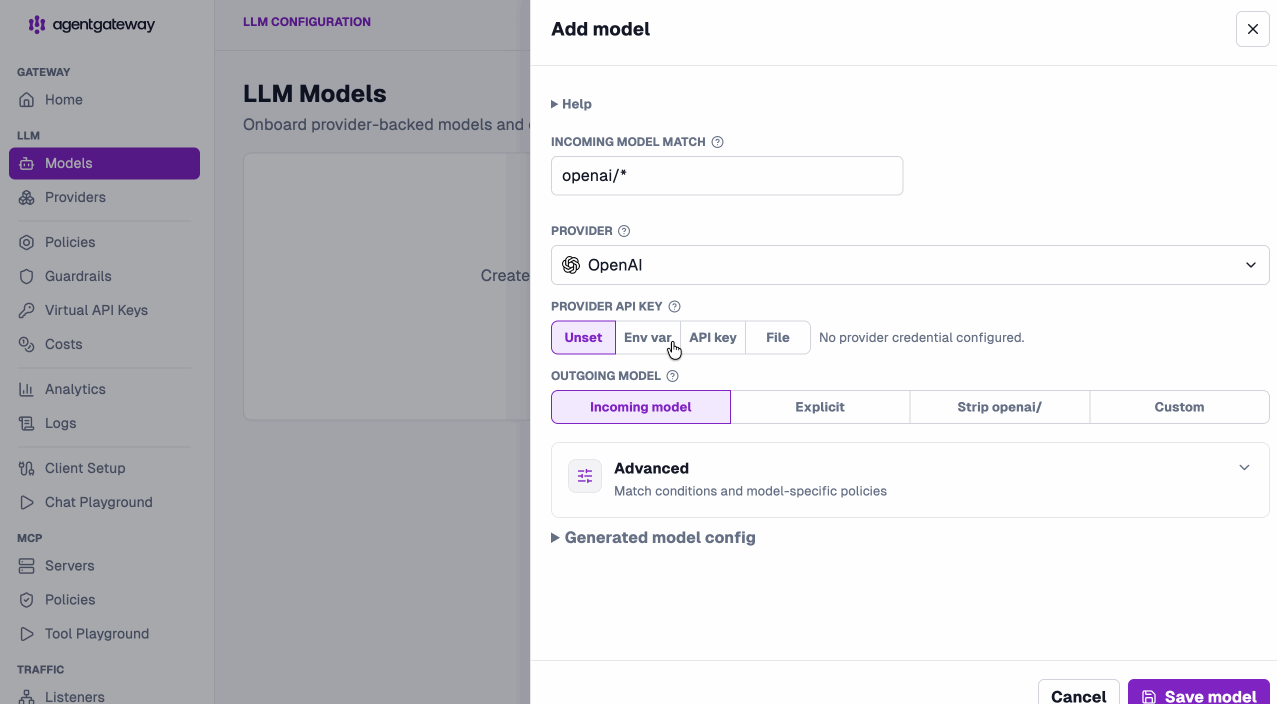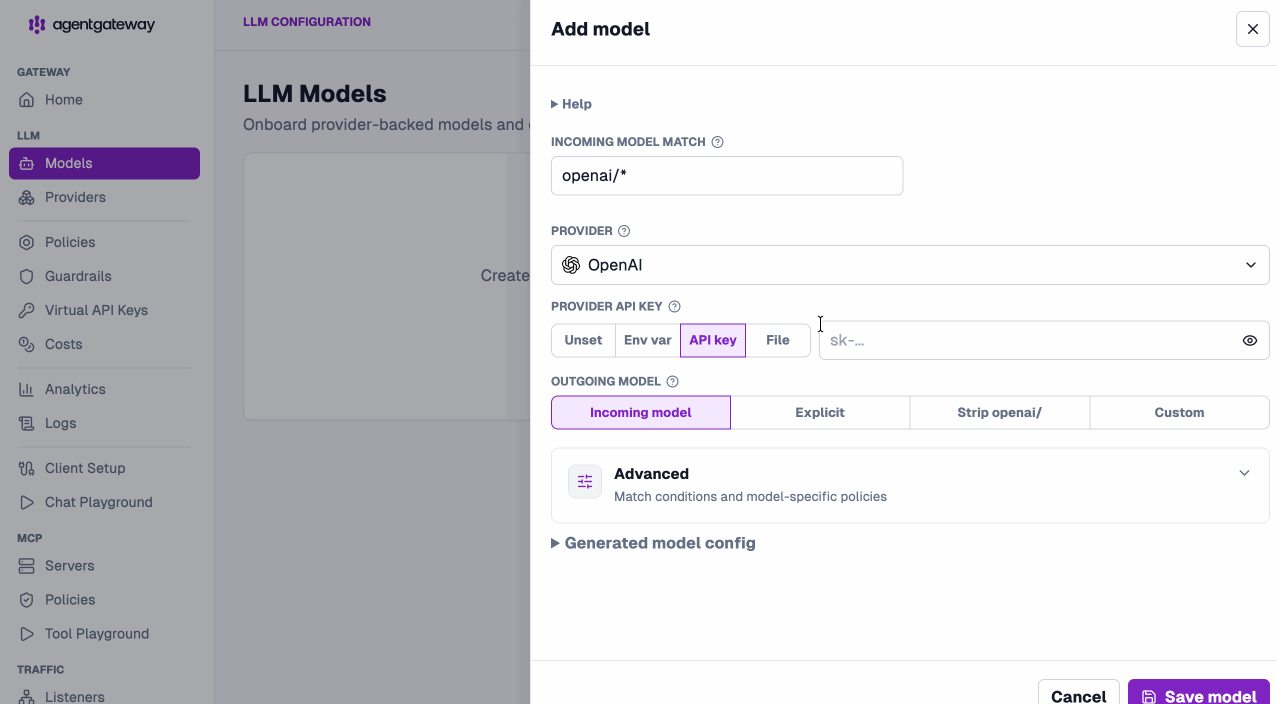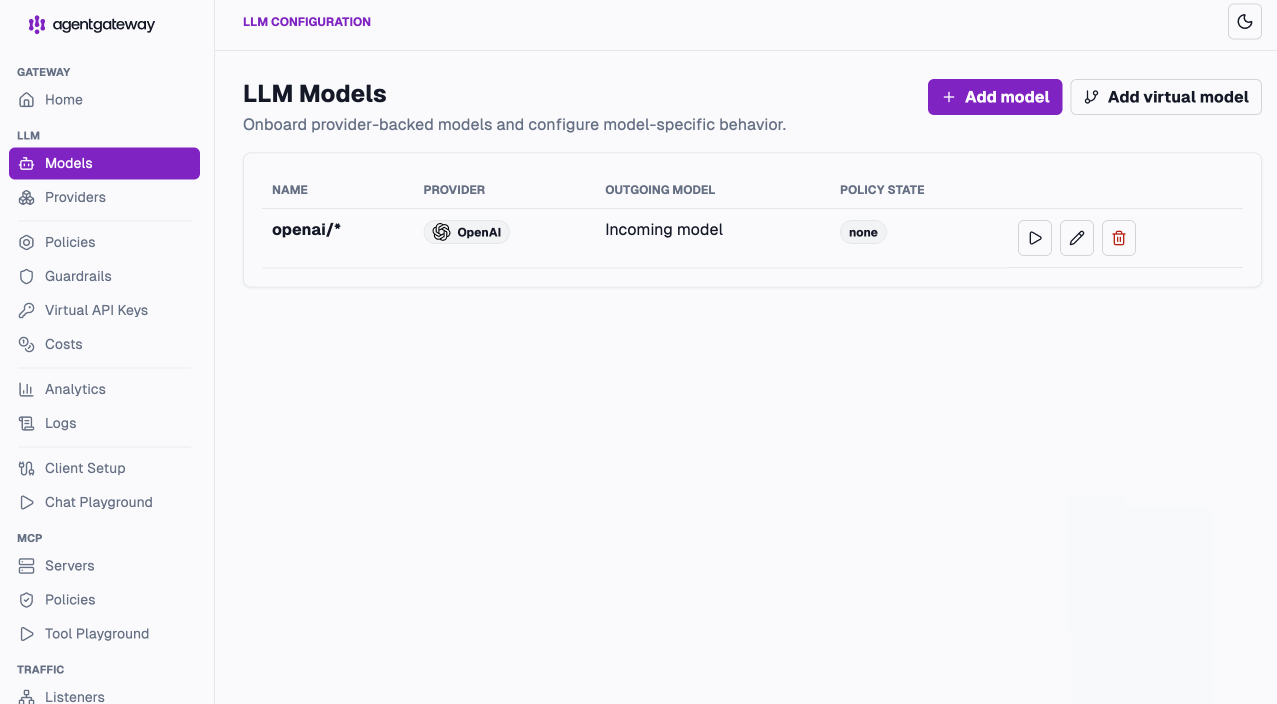
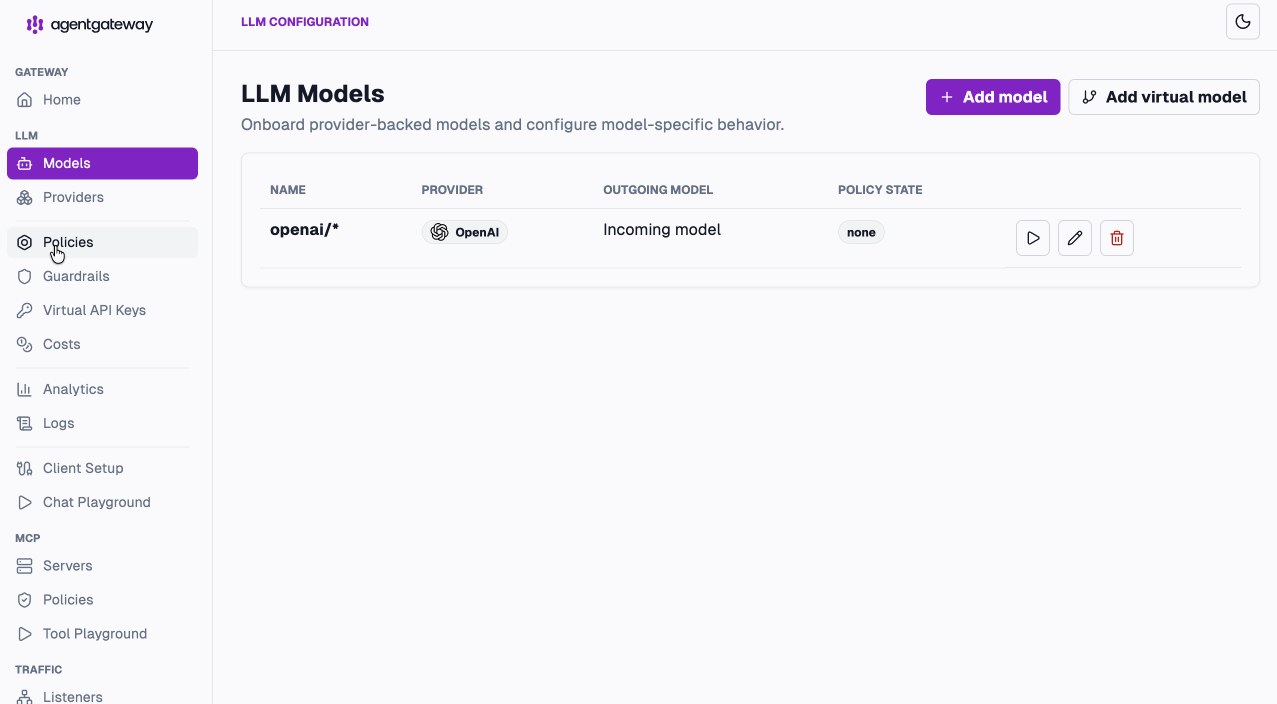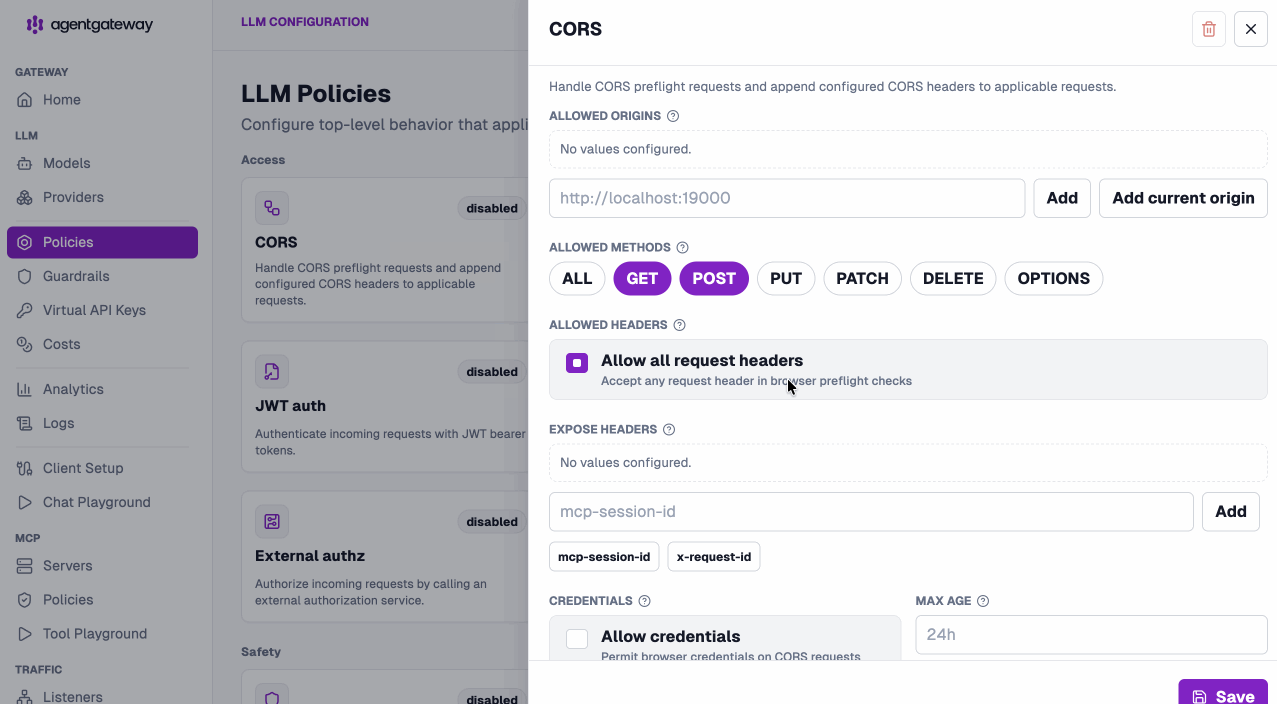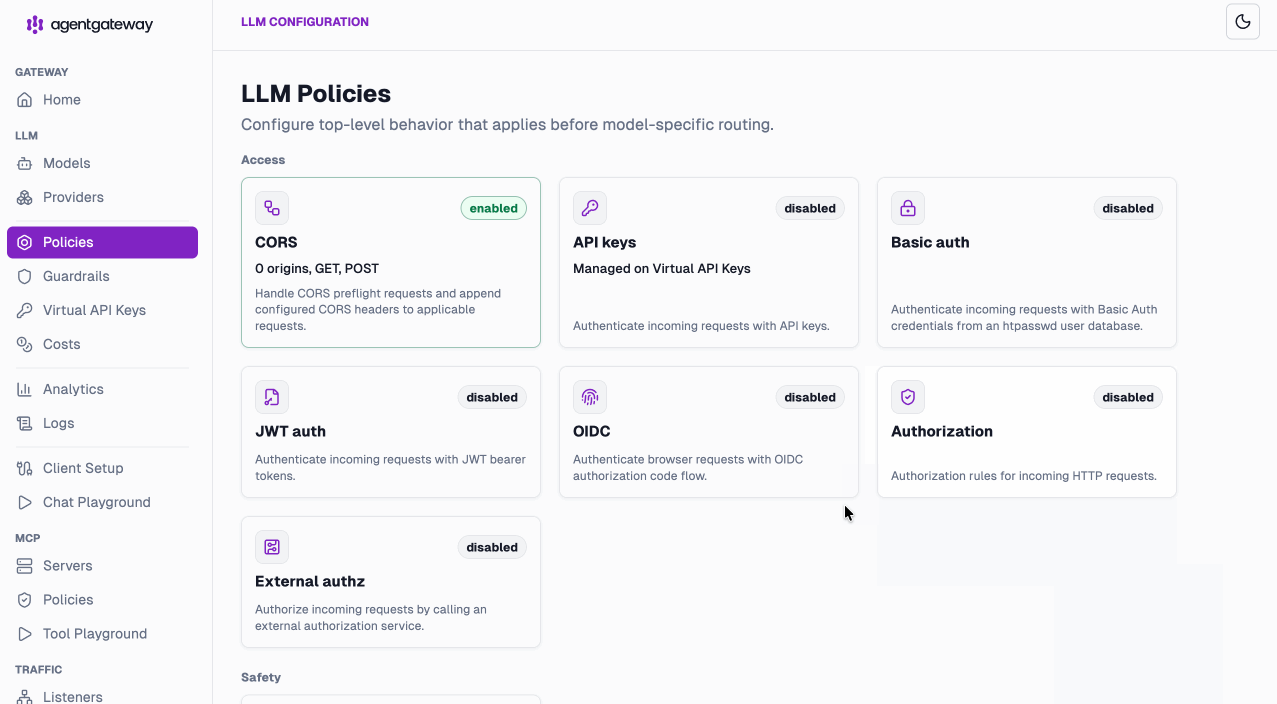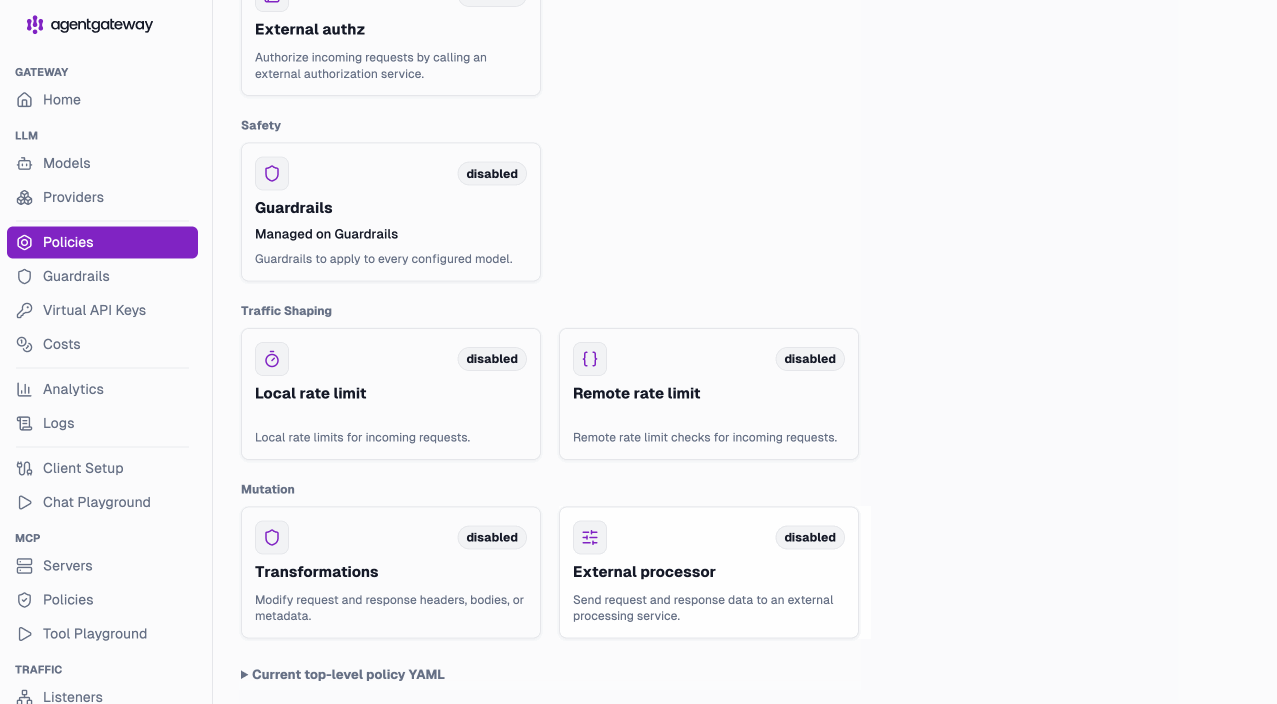
Apply policies without leaving the LLM layer. CORS, API keys, external authz, OIDC, JWT, and rate limiting are all configurable per model and visible at a glance.
Add guardrails with a click. Built-in detectors, custom regex, webhooks, OpenAI moderation, Bedrock Guardrails, and Google Model Armor — request and response guards, straight from the UI.
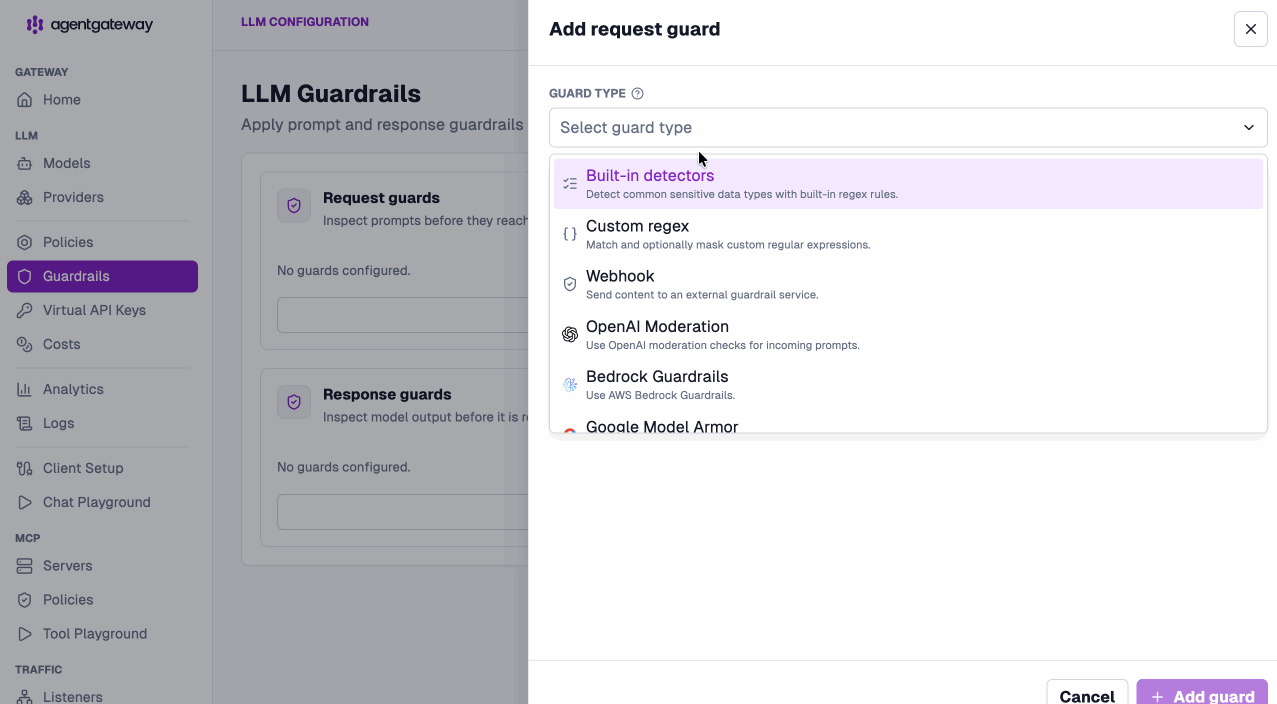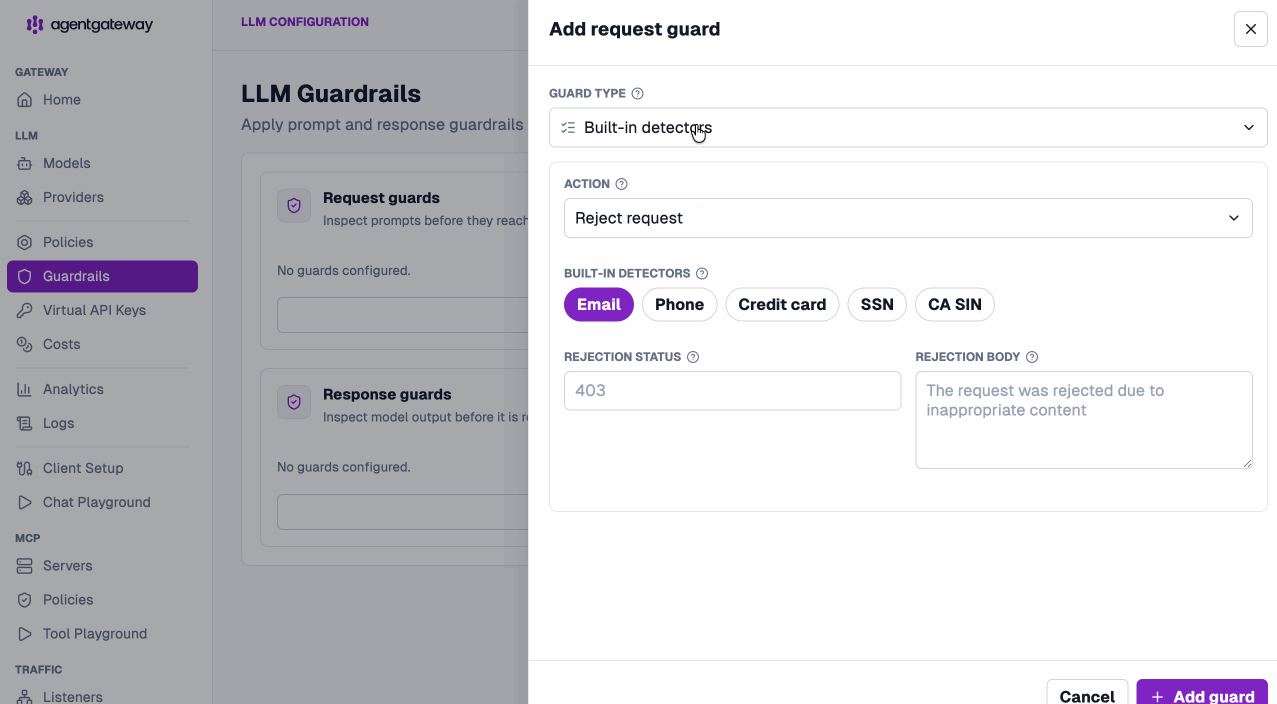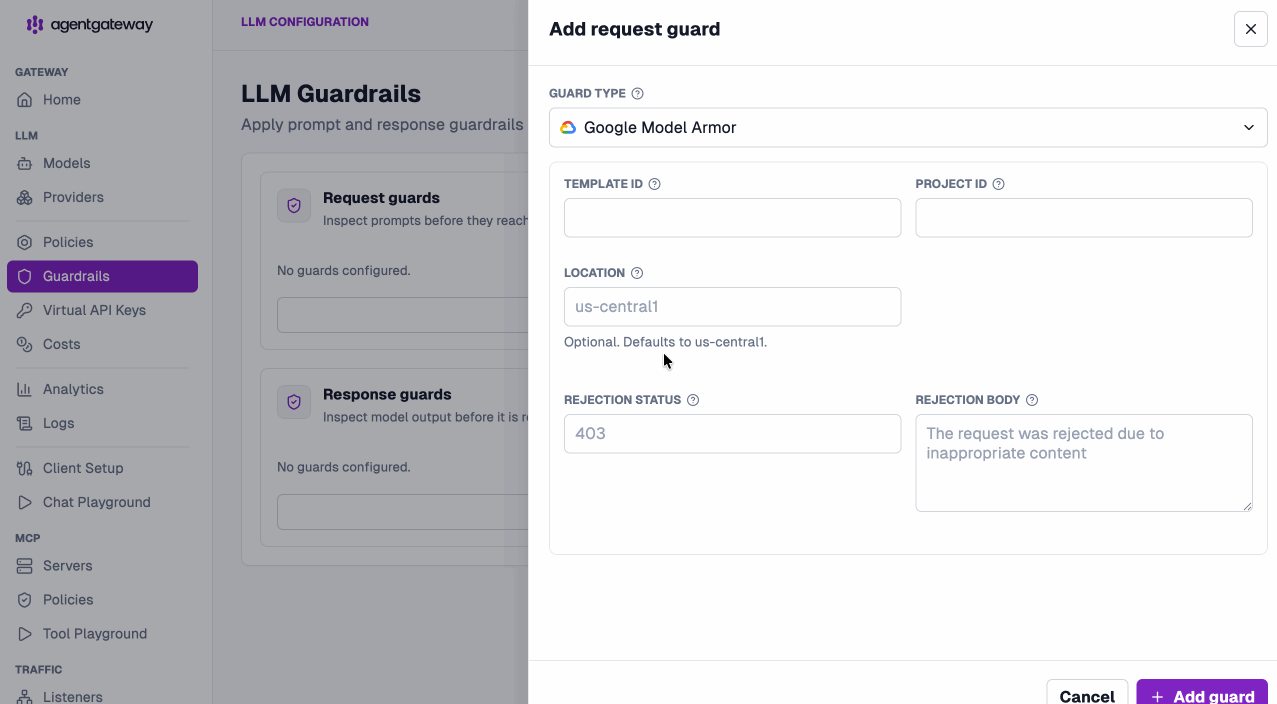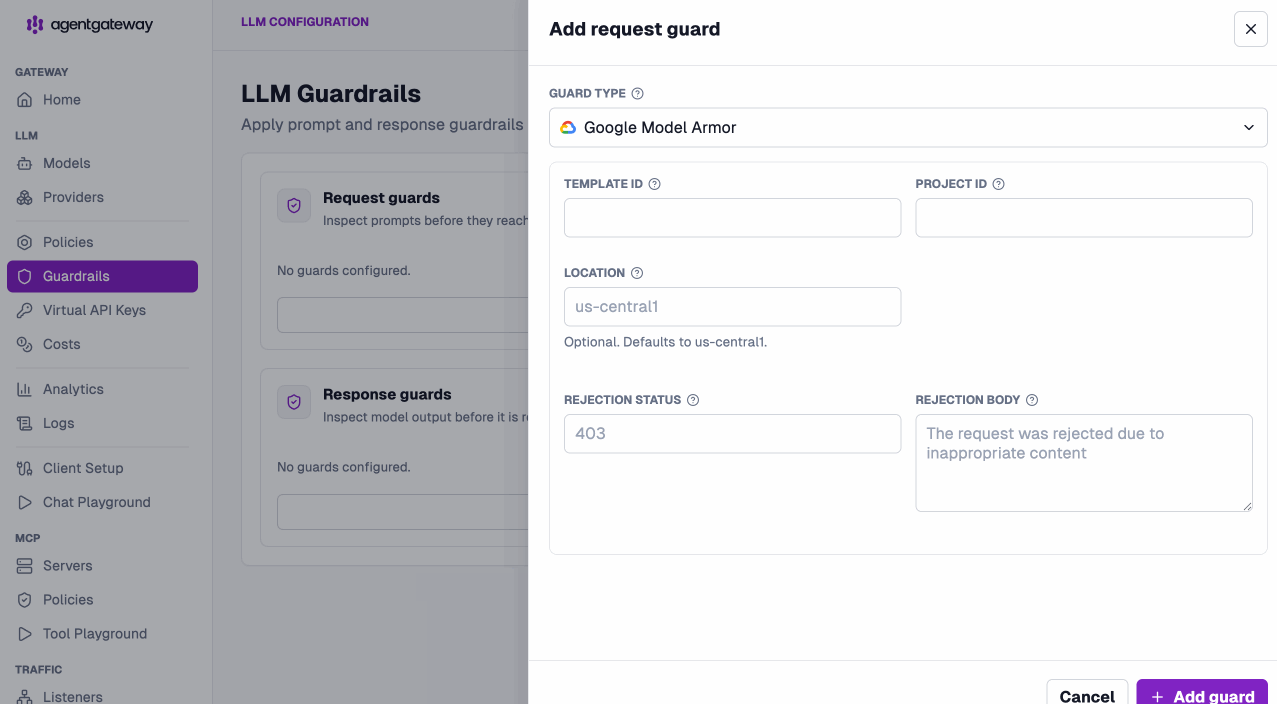
Configure once at the LLM layer, and it just works everywhere.
New: AI Cost & Analysis — every token, every dollar, attributed
No more guessing. No more scraping logs to figure out your burn rate. Agentgateway v1.3.0 turns every request into a measured, attributed, exportable data point — giving you full token and dollar analysis across everything flowing through the gateway.
- Configure cost rates per model, or import the official provider tables
- Every request calculates its exact cost and token counts (input, output, total)
- Token and cost data is surfaced in logs, traces, metrics, the UI, and agctl
But the real unlock is attribution. Agentgateway doesn’t just tell you what you spent — it tells you who spent it, on what, and through which tool. The Analytics view lets you slice token usage and dollar cost across every dimension that matters, and measure by tokens or cost:
- Per user — see exactly which developer or service account is driving spend, down to the individual
user@example.com. - Per team — roll usage up by group so you can charge back to the right cost center and spot the team that just 10x’d its Opus bill.
- Per coding tool / agent — break spend down by user agent, so you can compare what Claude Code, Cursor, GitHub Copilot, and your own autonomous agents are actually costing you across the org. When finance asks “is the Cursor rollout worth it?”, you have the number.
- Per model —
claude-opus-4-7vsclaude-sonnet-4-6vsgpt-5.1, side by side, so you know where the tokens are really going. - Per provider — compare OpenAI, Anthropic, Bedrock, and the rest at a glance to inform routing and contract decisions.
Mix and match the filters — “how much did the support team spend on Claude through Cursor this week?” is now a two-click question, not a data-engineering project. And it’s not just LLMs: because LLM, MCP, and A2A traffic all flow through the same gateway, you get one consistent, visual picture of how your entire agentic stack is being consumed — tokens, calls, and dollars, side by side.
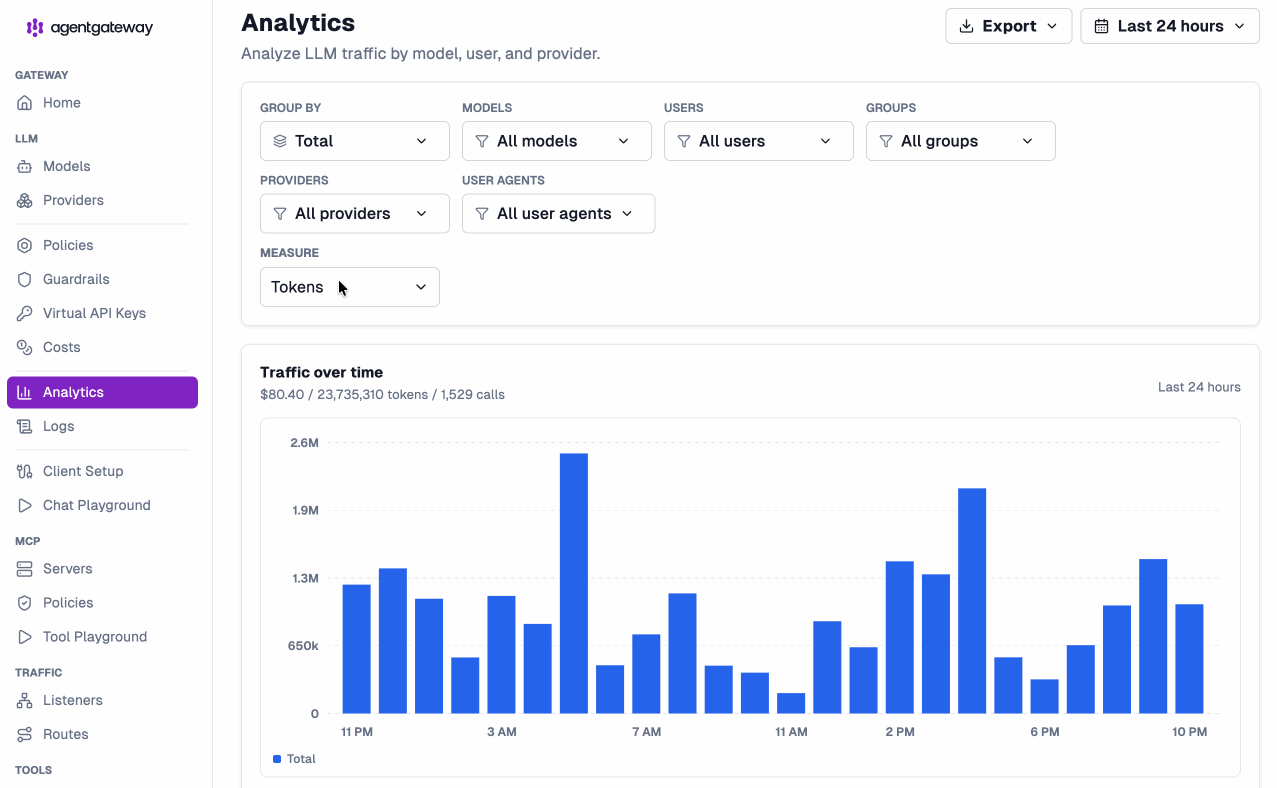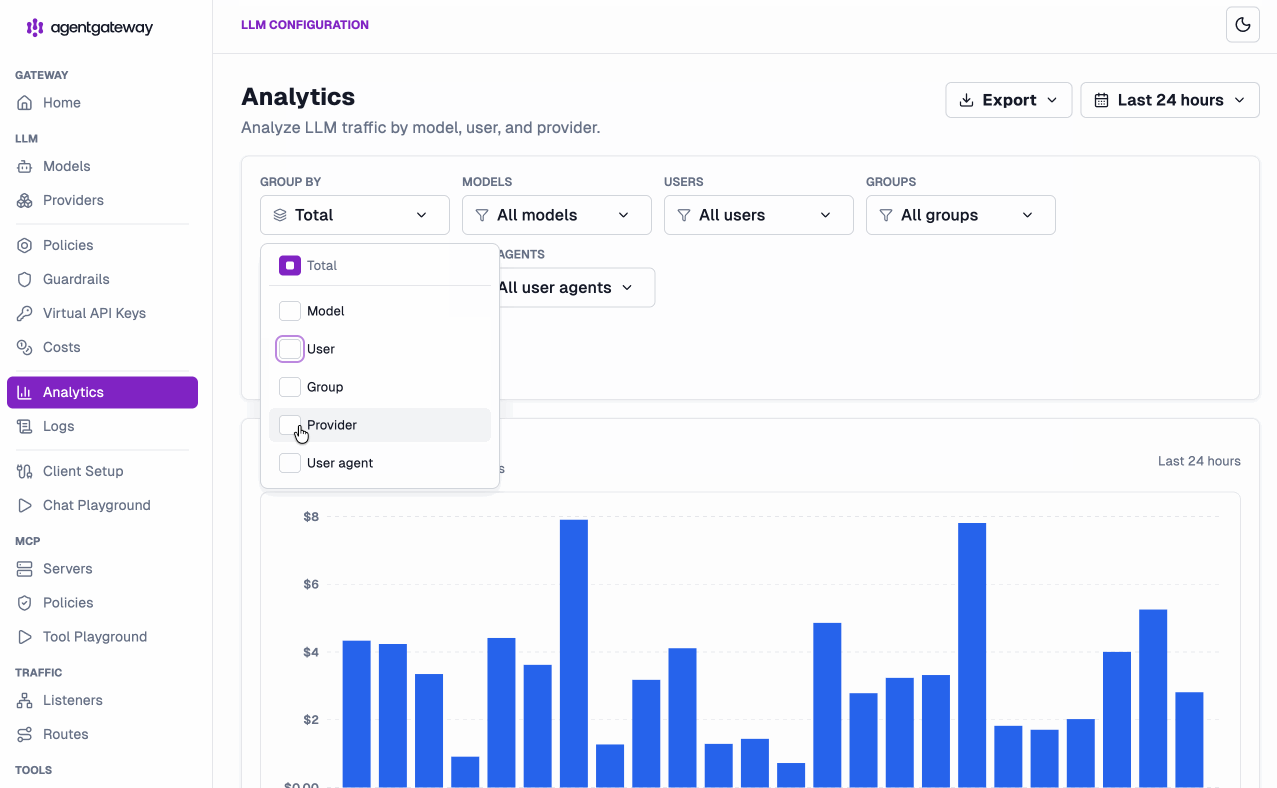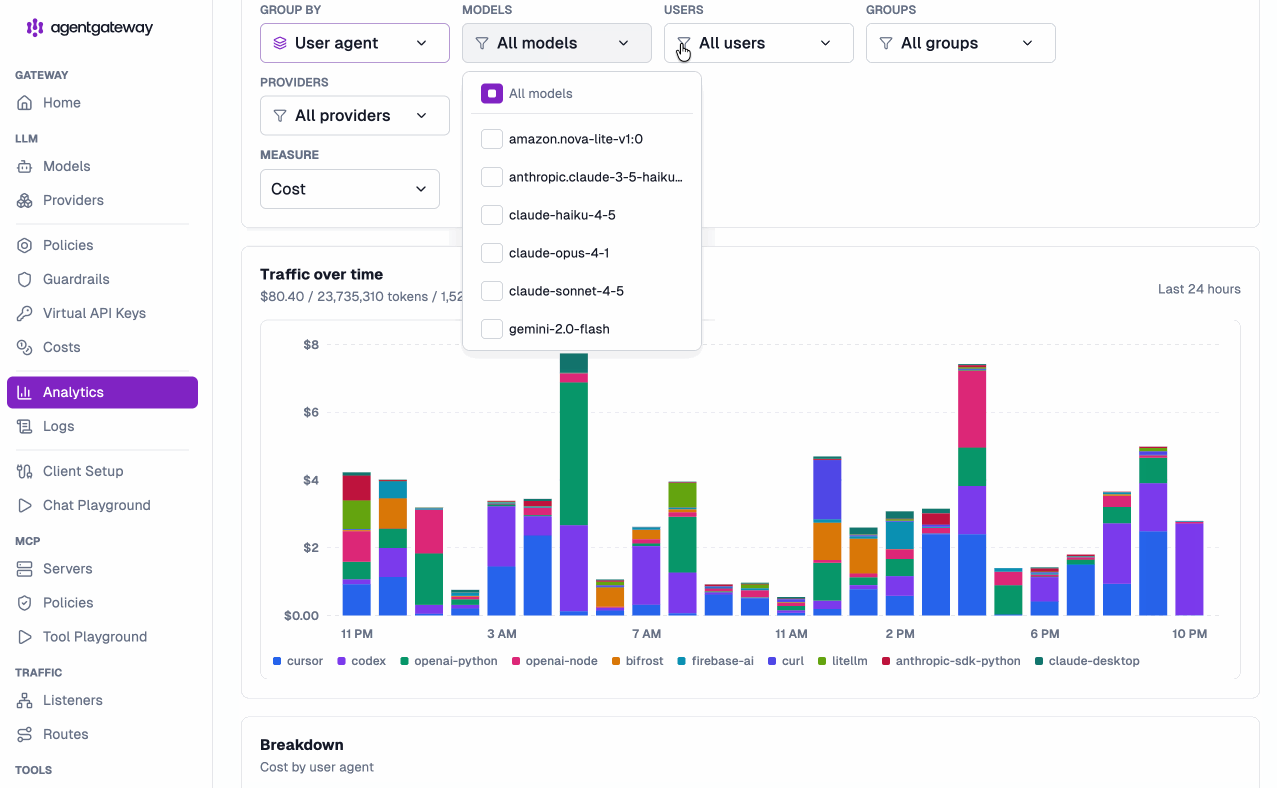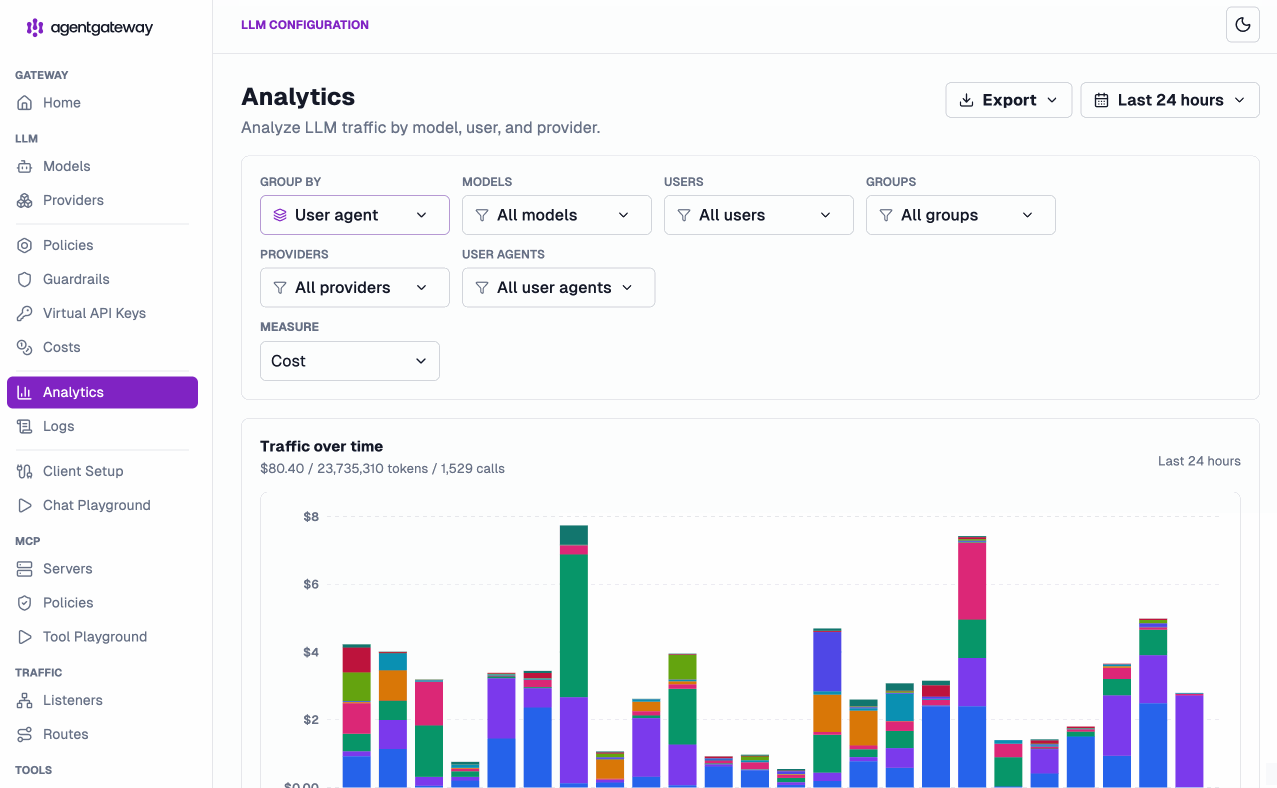
Need the numbers somewhere else? Export the report straight from the Analytics view and hand it to finance, drop it into a chargeback spreadsheet, or feed it into your own BI pipeline.
Because attribution lives at the gateway, you can also act on it with the same policy engine you already use for auth and rate limiting: set budgets, alert on spend, enforce hard quotas per team, or automatically route a cost-sensitive consumer to a cheaper model.
And it’s not just aggregate dashboards. The Logs view captures LLM, MCP, and A2A calls in one place — drill into any individual request and see exact duration, input/output tokens, dollar cost, and the user, group, and provider it was attributed to:
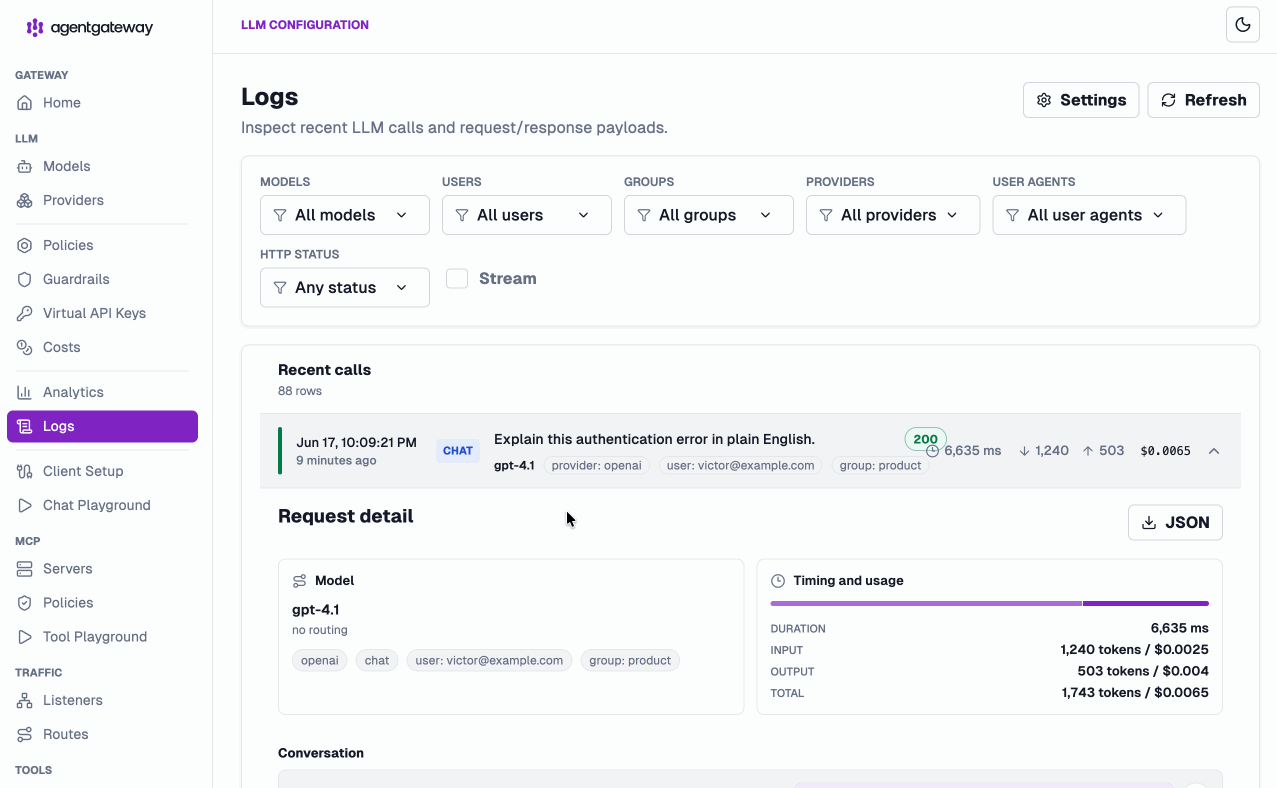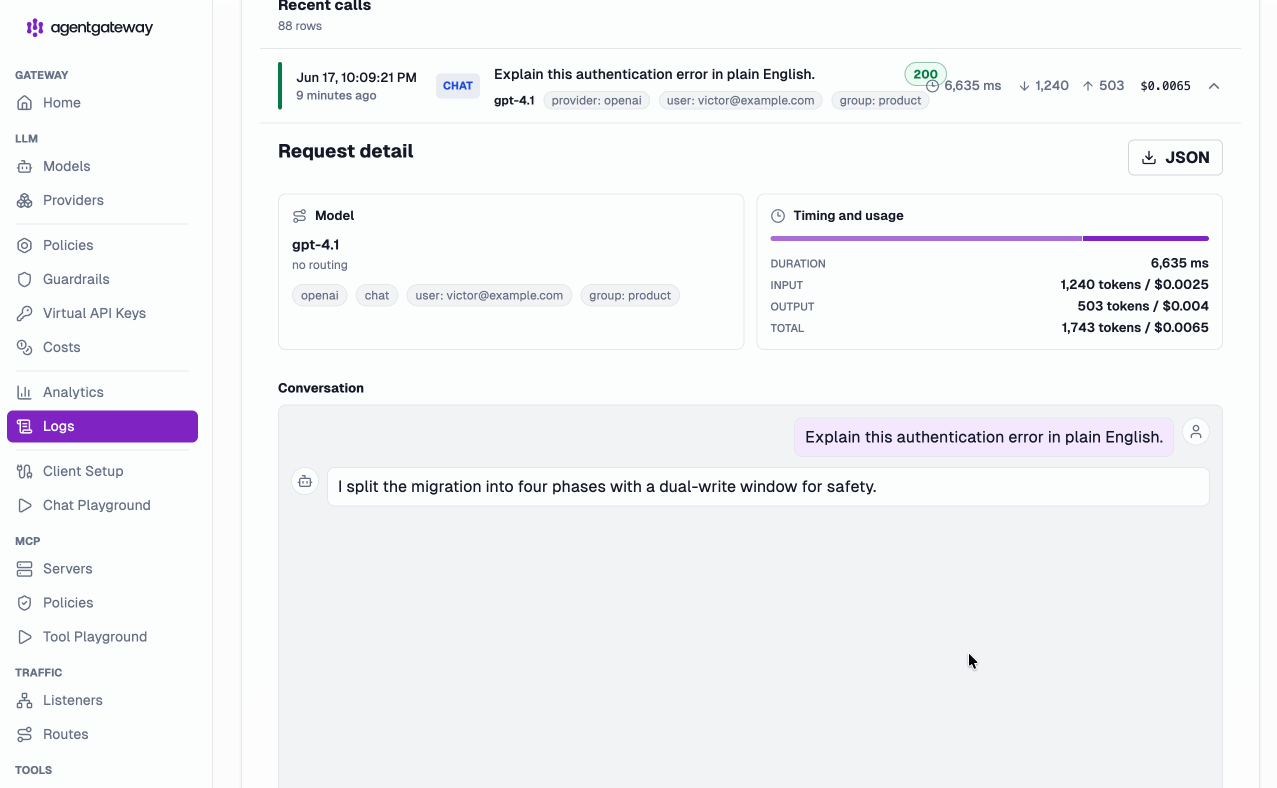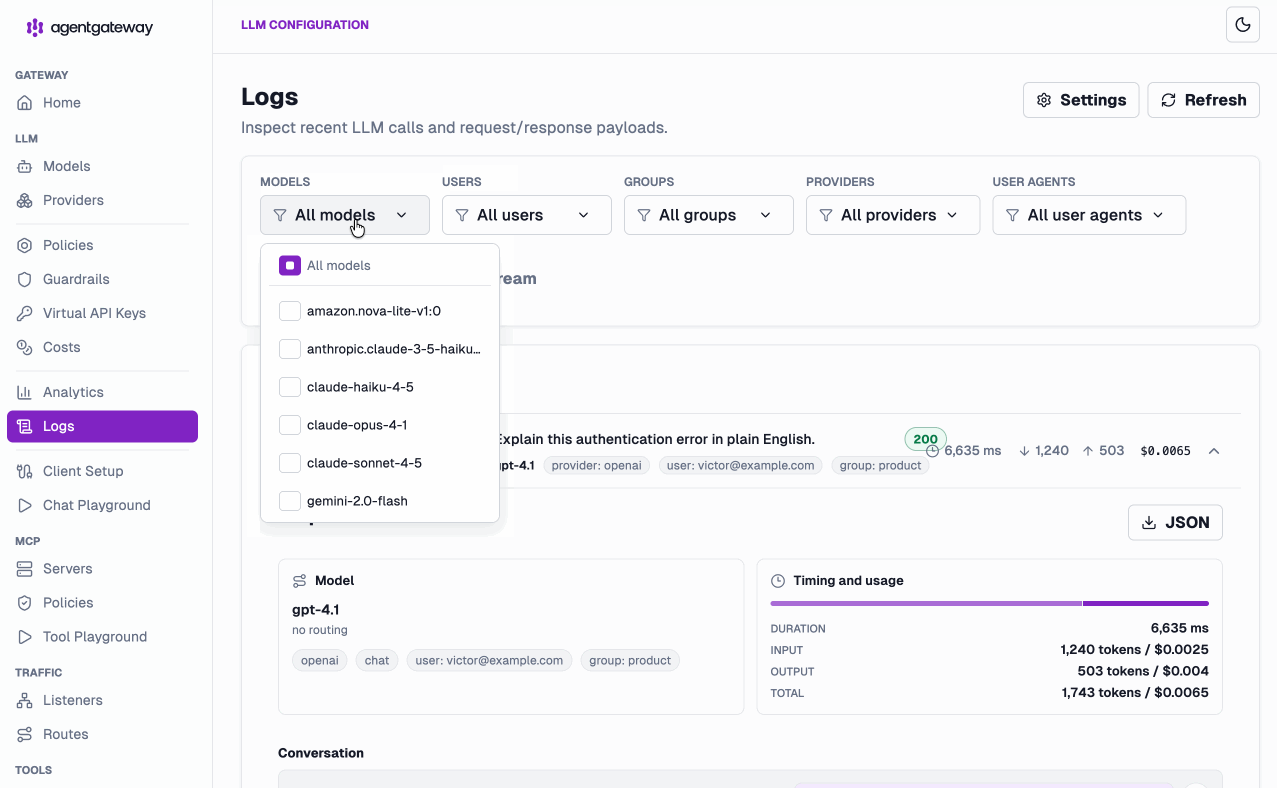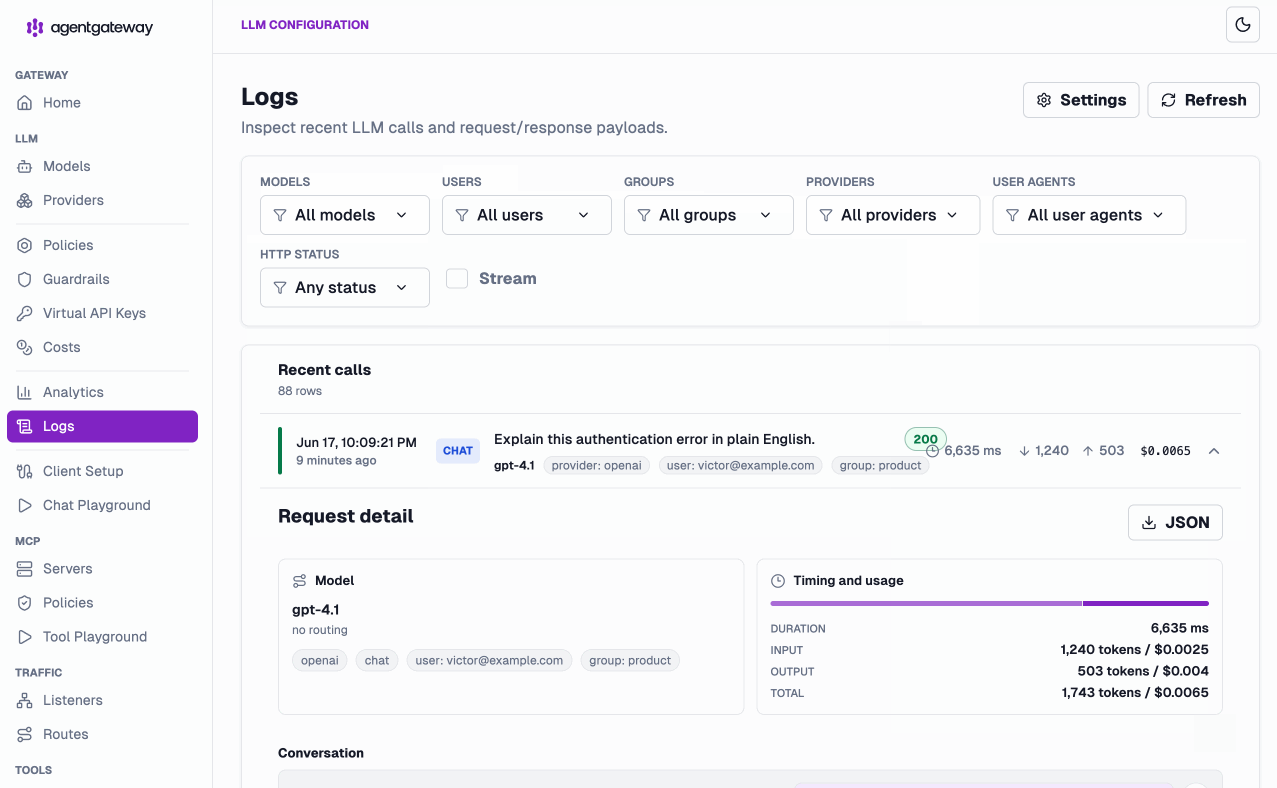
Virtual models — route smarter, not harder
Real model routing is rarely “send everything to one model.” You want to A/B test a new release against the incumbent, fall back to a cheaper model when the primary is throttled, or send long-context requests somewhere with a bigger window. Historically that meant routing logic baked into every client, or a custom proxy nobody wanted to own.
Virtual models move that decision into the gateway. A virtual model is a synthetic model — it has a name like any other, but instead of pointing at a single backend, it applies a routing strategy across several real models. Your client just sends the virtual model’s name in the request body; the gateway decides where each request actually goes.

Three strategies ship in v1.3.0, with more planned:
- Weighted — split traffic by percentage across models. Send 70% to your current production model and 30% to a candidate to A/B test quality or cost before you commit. Dial the split without touching a single client.
- Failover — order a list of models by preference. If the primary returns errors or gets rate-limited, the gateway automatically retries the next one — so a provider hiccup degrades gracefully to a fallback instead of failing the request.
- Conditional — branch on the request itself using CEL. Route by user tier, prompt length, headers, or any attribute the gateway can see — for example, send premium users to a frontier model and everyone else to a cheaper one.
The win is decoupling: routing policy lives in one place, owned by the platform team, and every consumer benefits at once. Want to flip the A/B split, add a fallback, or move a tier to a new model? Change the virtual model — no client changes, ever — and it takes effect everywhere instantly.
Reusability and a provider explosion
- Reusable providers and guardrails — define a provider or guardrail once and reference it across many models. Managing 50 OpenAI-compatible models? Done.
- Custom provider — reach providers without built-in support. More flexible than the OpenAI +
base_urlhack, and the recommended path for anything non-first-class. - 13 brand-new first-class providers — Mistral, Hugging Face, Cohere, and ten more.
- Streaming guardrails — guardrails now apply to streaming requests too, and webhook guardrails gain a
failureMode(fail-open or fail-closed). - Shared guardrails in standalone — declare guardrails once as a top-level resource instead of repeating the block on every route.
This is the release where managing many models stops feeling like a spreadsheet nightmare.
Beyond the LLM layer — the whole platform leveled up
v1.3.0 isn’t only about LLMs. Here’s everything else that landed.
Request handling & extensibility
- Request buffering — traffic policies can buffer request bodies before forwarding, so policies and extensions get full request-body access before backend selection.
- External processing — richer processing-mode configuration, and ext_proc can now return an
ImmediateResponsefrom the request- and response-body phases. - ExtMCP — MCP-aware external auth and external processing, so your services decide using MCP request context, not just generic HTTP metadata.
Authorization & auth
- Authorization can now run in the pre-routing phase
- Per-model LLM authorization — scope who can call which model
- External-auth cache TTL as an expression, plus ext-authz caching
- Credential-location expressions fixed and expanded; scheme derived from
X-Forwarded-Proto
LLM gateway
- Rerank request/response support across providers
- Custom LLM providers for
InferencePoolbackends - More precise per-model matching (prefers exact matches)
- Bedrock: detect-passthrough, Application Inference Profile prompt cache, Anthropic beta-header allowlist, host override, URL-encoded model IDs, reasoning-signature replay
- Anthropic: system messages and extra-high thinking
- Local LLM: TLS and CORS support
- Latency and throughput telemetry attributes on LLM requests
MCP
- Okta as a first-class MCP authentication provider
- Resource subscribe/unsubscribe, improved multiplexing and list behavior
- Advertised prompt/resource/tool list-change capabilities, plus broader protocol-compliance fixes
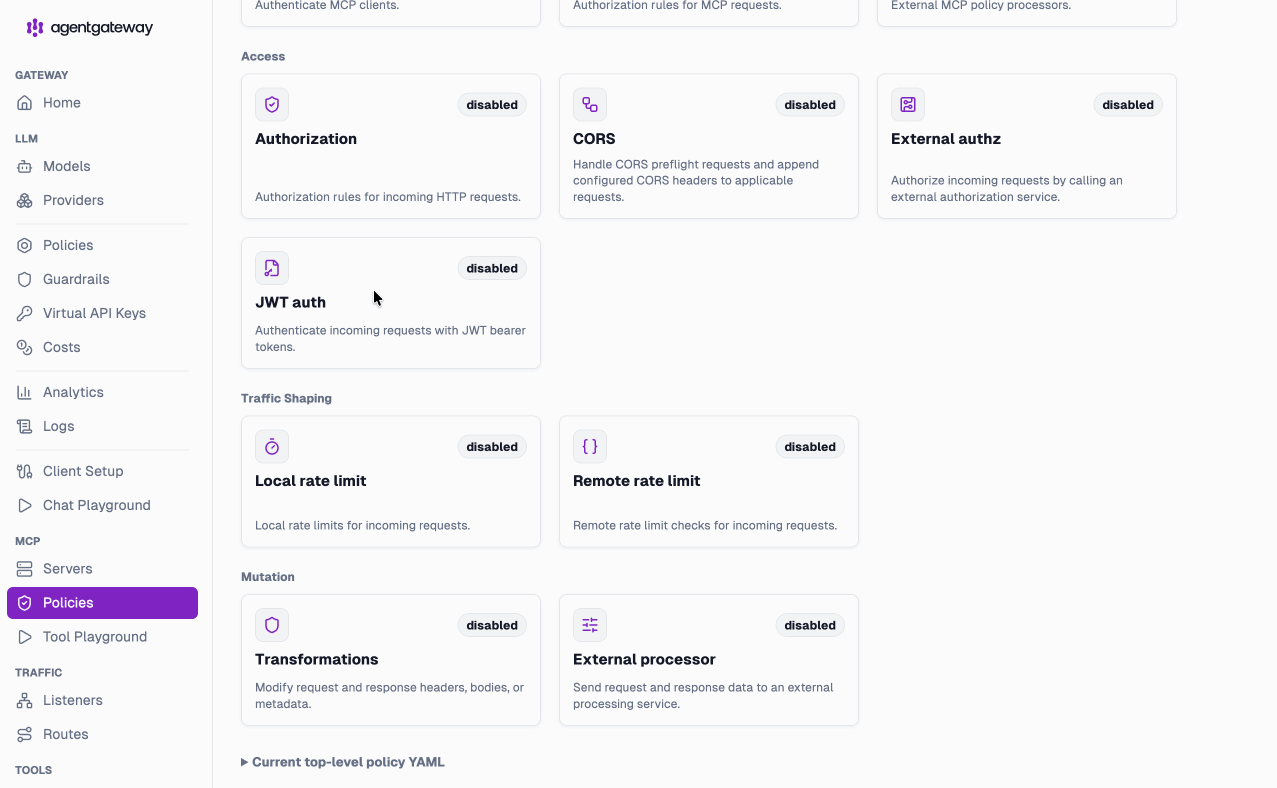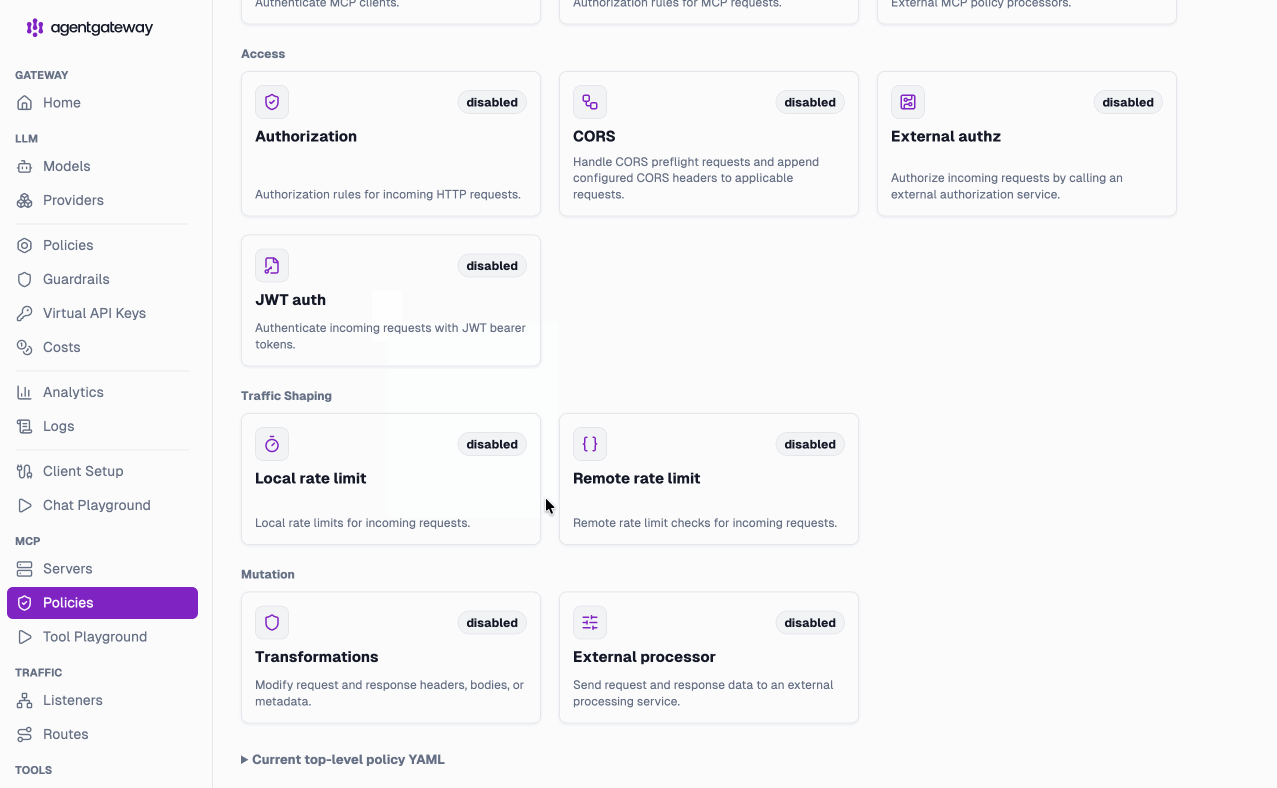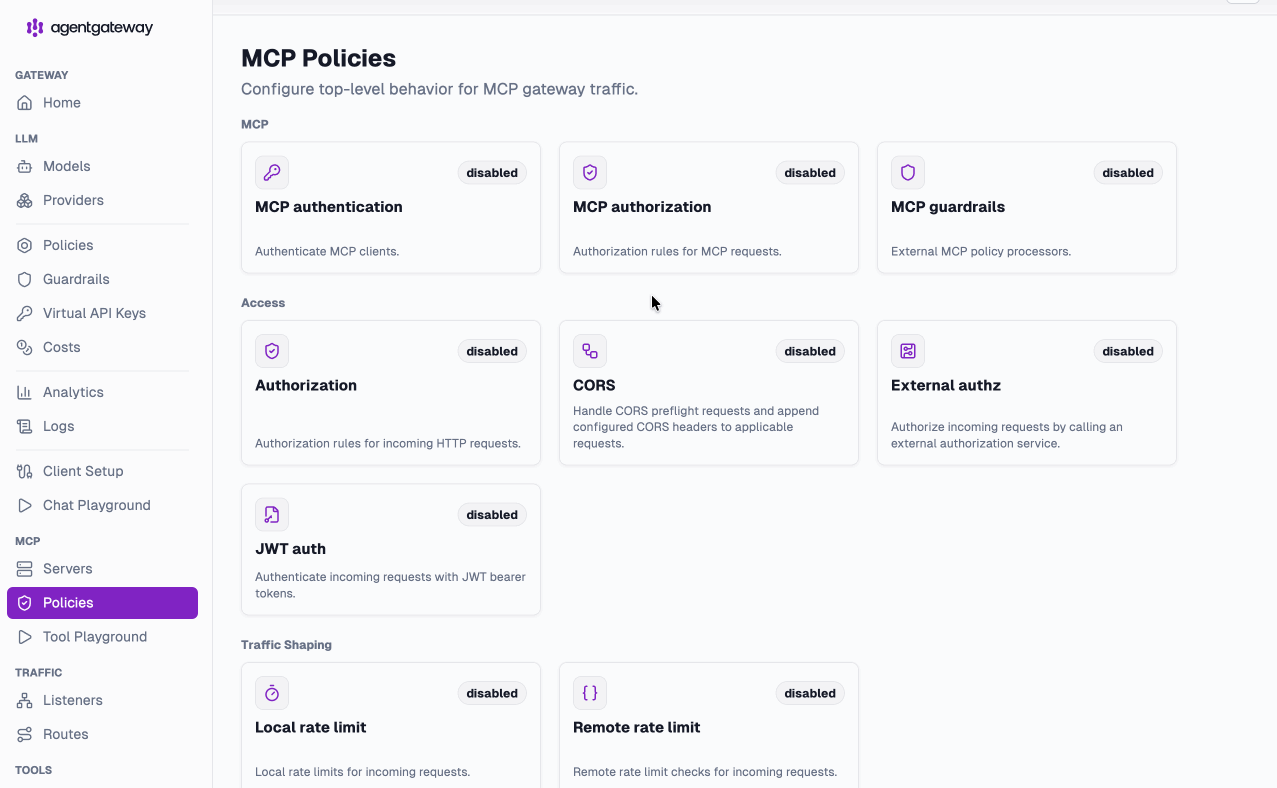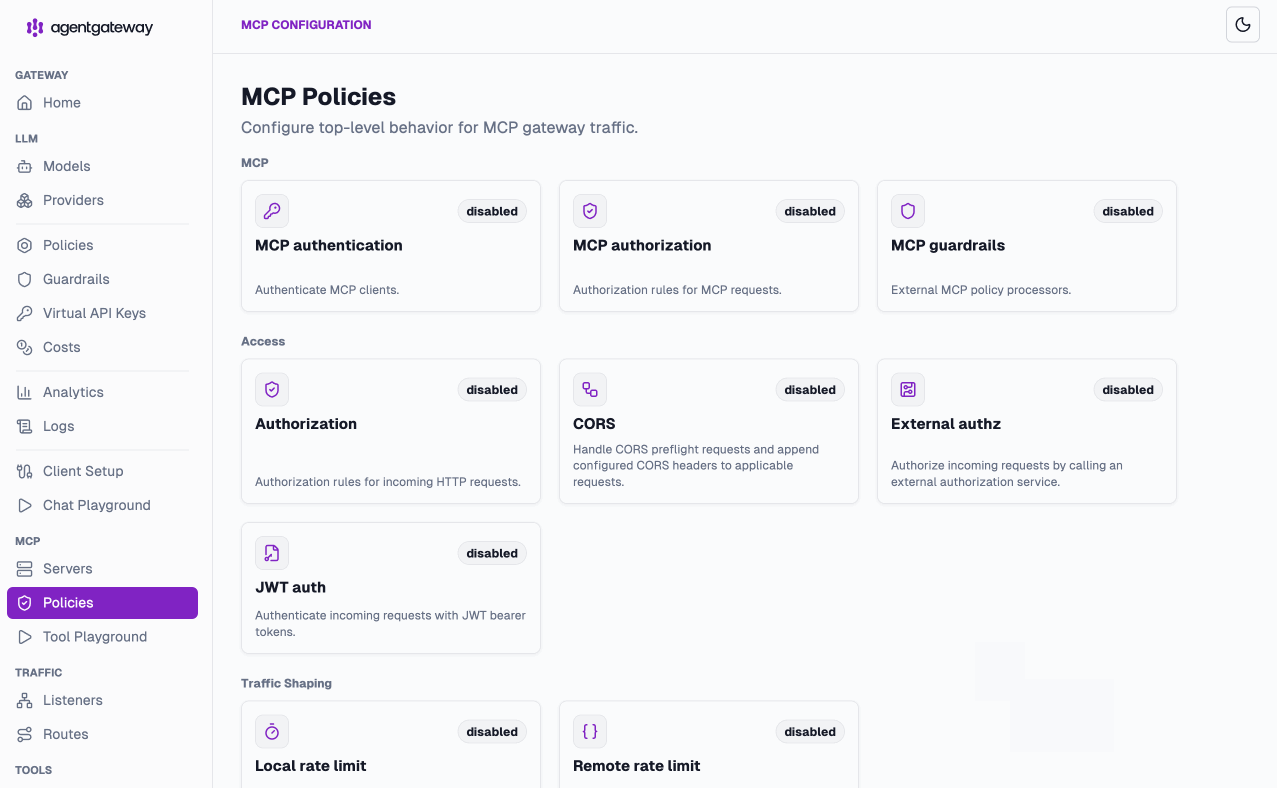
And like the LLM layer, MCP gets its own native policy views — access, traffic shaping, and mutation, configurable per server:
TLS, networking & policy
- Dynamic SSL certificates for Kubernetes listener TLS
- Generalized backend TLS and backend references, with a new
BackendReferenceGrantMode - Policy inheritance strategy configuration, and composable AI backend policies
- Terminating inbound
CONNECT, configurable admin interfaces (including UDS), AWS AssumeRole, custom AWS service names, and mTLS cert passthrough via CEL
CEL & agctl
- New CEL helpers:
url.encode/url.decode, more timestamp conversions, bit ops on bytes,jwt.rawToken, gRPC status on responses, expressions in direct responses, and CEL-based retry conditions agctlgains proxy/controller log commands, aversioncommand with mismatch checks, route groups in config output, and evicted-backend visibility
Operations & observability
- Proxy timing measurements and a config-synchronization metric
- Request and connection IDs for troubleshooting
- Richer distributed traces — JSON mode, body snapshots, effective gateway/route policies, and raw-output file opening
A handful of fixes worth calling out: TCP route precedence, Gateway status when no listeners are valid, route-level OIDC cookie handling, capacity-weighted load balancing, backend eviction retries, and streaming-completion capture across Bedrock, Messages, and Responses API paths.
For the complete list of features and 50+ fixes, see the GitHub release notes.
Availability
Agentgateway v1.3.0 is available now. Grab the Docker images, Helm charts, and binaries from the GitHub release page, then follow the quick start guide for Kubernetes or standalone.
Contributors
This release happened because 41 contributors showed up between v1.2.1 and v1.3.0 — code, reviews, docs, bug reports, and the unglamorous CI work that keeps a fast-moving project on the rails. 21 of them made their first commit this cycle alone.
A special shout-out to the people who drove the most change this release:
…alongside everyone whose fixes, features, and feedback made the rest of the release possible. The full list of contributors is in the v1.3.0 release notes.
Get involved
Star the repo at github.com/agentgateway/agentgateway, join us on Discord, and come hang out at our community meetings.